 Comparsion of data formats for storaging and transmitting.
Comparsion of data formats for storaging and transmitting.Usage domains:
- APIs: Protobuffers, Thrift, Avro
- storage for data analysis (Hive, Impala, ...): ORC, Parquet, Avro
- data storage: Sequence files, compressed text (gzip, bzip2, lz4), Avro
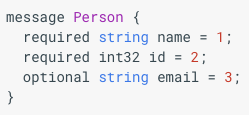
Protobuf
- = Google's protocol buffers
- defines one record serialisation
- suitable for data transportation
- good for optional attributes - message contains just data for present attributes
- attributes are identified by id
- schema evolution
- similar: capnproto
Thrift
- developed in Facebook, newer than Protobuf
- slightly slower and bigger than Protobuf
- more complex data types than Protobuf
- RPC implementation
- schema evolution
Avro
- row-based
- defines record and also container serialisation
- schema evolution
- IDL uses JSON
- splittable in Hadoop
- data corruption of container: sync markers between data blocks => after corruption, all records to the end of the particular block will be lost
- good for complex tables with strings
- schema in the header => no need of external schema
- rows can be appended
Parquet + ORC
- column-based
- great when reading subset of attributes
- schema in the footer
- splittable in Hadoop
- stores statistics of columns (min, max, count); ORC has indexes
- hierarchical data structures
- write-once formats